If you are still measuring your brand’s digital health solely by Google Search Console rankings, you’re looking at a shrinking slice of the pie. The shift toward Generative Engine Optimization (GEO) isn't a future trend; it’s a current operational gap. For years, we’ve optimized for blue links. Now, we have to optimize for the citation footnoted in a Perplexity answer or the brand mentioned in a ChatGPT recommendation.
Recent data suggests that standard SEO tactics—specifically the heavy use of Schema.org markup—have little to no correlation with citation frequency in LLM responses. A May 2026 study by Ahrefs [S1] confirmed that adding schema didn't boost citations across any major generative platform. This debunked the 'Schema-as-a-Silver-Bullet' theory that many agencies sold throughout 2025. If the technical plumbing doesn't guarantee a mention, what does?
By the end of this guide, you will have a repeatable framework for auditing your brand's 'Citation Visibility' and a roadmap for restructuring your content so LLMs actually retrieve and credit it. You'll need access to ChatGPT Plus, Perplexity Pro, and a spreadsheet to track your baseline metrics.
TL;DR
- Schema isn't the savior: LLMs prioritize semantic relevance and high-authority third-party mentions over technical markup.
- Audit the 'Citation Gap': Use specific, high-intent prompts to see where competitors are out-citing you in generative answers.
- Human-centricity wins: Content that feels like 'unpaid marketing work' [S2] is being deprioritized in favor of genuine, data-backed human insights [S3].
- Niche Authority: Citations are earned through specific data points, unique quotes, and clear brand-to-solution mapping.
Step 1: Baseline the 'Referential Integrity' of Your Brand
Before you can fix your visibility, you have to understand how the LLM perceives your brand’s core identity. This isn't about ranking for 'best shoes'; it's about whether the model knows who you are without being prompted for your URL. We call this 'Referential Integrity.' If an LLM cannot define your brand without browsing the live web, your training data footprint is too shallow.
What to do: Open a fresh session in ChatGPT (GPT-4o or later) and Perplexity. Do not provide your URL. Use the following prompt: 'Analyze the market position and key product features of [Brand Name]. Cite the primary sources used for this analysis.'
Why it matters: This tells you what the model 'knows' from its training data versus what it 'retrieves' via RAG (Retrieval-Augmented Generation). If the model relies on Reddit threads from 2023 or outdated press releases, you have a training lag issue. If it returns a 'I don't have enough information' response, your brand lacks sufficient digital density.

Common Pitfall: Many marketers use their own brand name in a biased prompt like 'Why is [Brand] the best?' This triggers the model's sycophancy bias. You need neutral, objective prompts to see the real citation map.
Step 2: Map the Competitor Citation Overlap
In generative search, the 'winner' isn't the one with the highest DA (Domain Authority), but the one that provides the most 'citable' answer to a specific user intent. Perplexity, in particular, often favors niche blogs or specialized industry reports over massive corporate homepages if the niche site provides a direct answer structure.
What to do: Identify your top 5 high-intent keywords. For each, ask Perplexity: 'What are the top 3 solutions for [Problem], and what are the pros/cons of each?' Document which brands are cited in the footnotes. Note the source of the citation. Is it the brand’s own site, a G2 review, a Reddit comment, or a news article?
Why it matters: You’ll often find that your competitors are being cited through third-party mentions rather than their own domains. If 80% of citations for your category come from Reddit or industry-specific forums, your SEO team’s focus on your blog is misplaced. You need a 'Surround Sound' strategy.
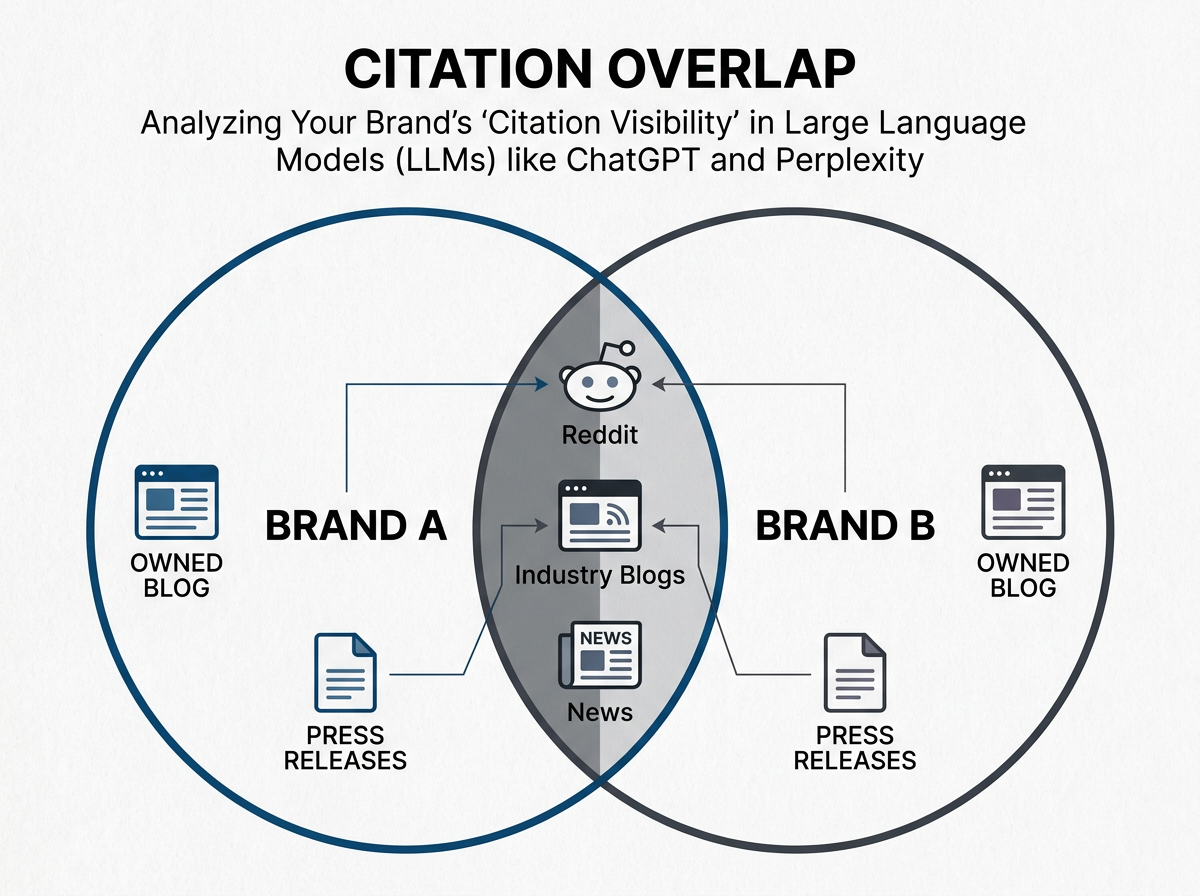
Common Pitfall: Ignoring the 'Source Type.' If Perplexity is citing a competitor's 2024 whitepaper and your 2026 blog post isn't appearing, it’s likely because the whitepaper has more 'structural density'—tables, clear headers, and statistical claims that LLMs find easy to parse.
Step 3: Audit for 'Semantic Density' and Data Tables
LLMs are essentially sophisticated pattern matchers. They love structured data, but not necessarily in the way Google likes Schema. They love human-readable structure. A 2,000-word essay is harder for a generative engine to summarize than a 500-word piece with a clear, data-heavy table.
What to do: Review your top-performing content. Are you using HTML tables? Are your H2s and H3s answering specific questions? Convert your key product comparisons and pricing models into clean, indexable tables. Use 'Entity-Attribute-Value' (EAV) mapping in your prose. Instead of saying 'Our software is fast,' say 'Our software has a [Attribute: Latency] of [Value: 20ms].'
Why it matters: When ChatGPT 'reads' a page via its browser tool, it looks for facts to extract. A table is a pre-extracted set of facts. This makes your content the 'path of least resistance' for the model to use as a citation. As noted in recent digital marketing discussions [S4], explaining this to clients is difficult because it feels like 'dumbing down' content, but it's actually about 'structuring for extraction.'

Common Pitfall: Over-optimizing for 'AI' and losing the human touch. As [S3] suggests, the most underrated skill in 2026 is creating content that feels human. If your table looks like it was generated by a bot, the LLM might parse it, but the user—the person actually reading the citation—won't trust it.
Step 4: The 'Unpaid Marketing' Ghosting Audit
There is a growing sentiment that social media has become 'unpaid marketing work' [S2], with users fleeing highly optimized brand content. LLMs are picking up on this shift. They are increasingly weighted to prioritize 'authentic' mentions in their 'Social' or 'Community' retrieval layers. If your brand is only mentioned in your own posts, you are invisible to the social-retrieval layer of AI search.
What to do: Search for your brand on Perplexity using the 'Social' focus mode. See if it can find any mentions of your product in 'organic' conversations from the last 90 days. If the only results are your own official accounts, you have a 'Social Citation Gap.'
Why it matters: Perplexity and OpenAI's SearchGPT (in limited release) increasingly use real-time social signals to validate brand claims. If you claim to have the 'best customer service' but Reddit is full of complaints about your 2026 security breach [S5], the AI will likely include that 'balanced' view in its answer, or skip citing you as a 'best' option entirely.
Common Pitfall: Thinking 'quantity' of mentions equals 'quality' of citations. Five high-upvote Reddit comments in a relevant subreddit (like r/DigitalMarketing or r/socialmedia) are worth more for AI citation than 5,000 bot-generated tweets.
Step 5: Verification — The 'Citation Lift' Test
How do you know if your changes worked? Unlike Google, where you can see a rank change in 24 hours, LLM citation windows vary based on the model’s 'freshness' index. Perplexity updates its index almost constantly; ChatGPT’s 'Search' feature does the same, while its base model training data is static.
What to do: After implementing 'extraction-friendly' changes (tables, clear entity mapping, third-party PR), wait 14 days. Re-run your prompts from Step 1 and Step 2. Use a 'Comparison Prompt': 'Compare [Your Brand] and [Competitor] based on [Specific Feature]. Why should I choose one over the other?'
Why it matters: You are looking for 'Citation Lift'—an increase in the number of times your URL appears in the footnotes OR an increase in the accuracy of the facts the AI attributes to you. If the AI is now correctly quoting your new pricing or a specific statistic you published, your optimization is working.
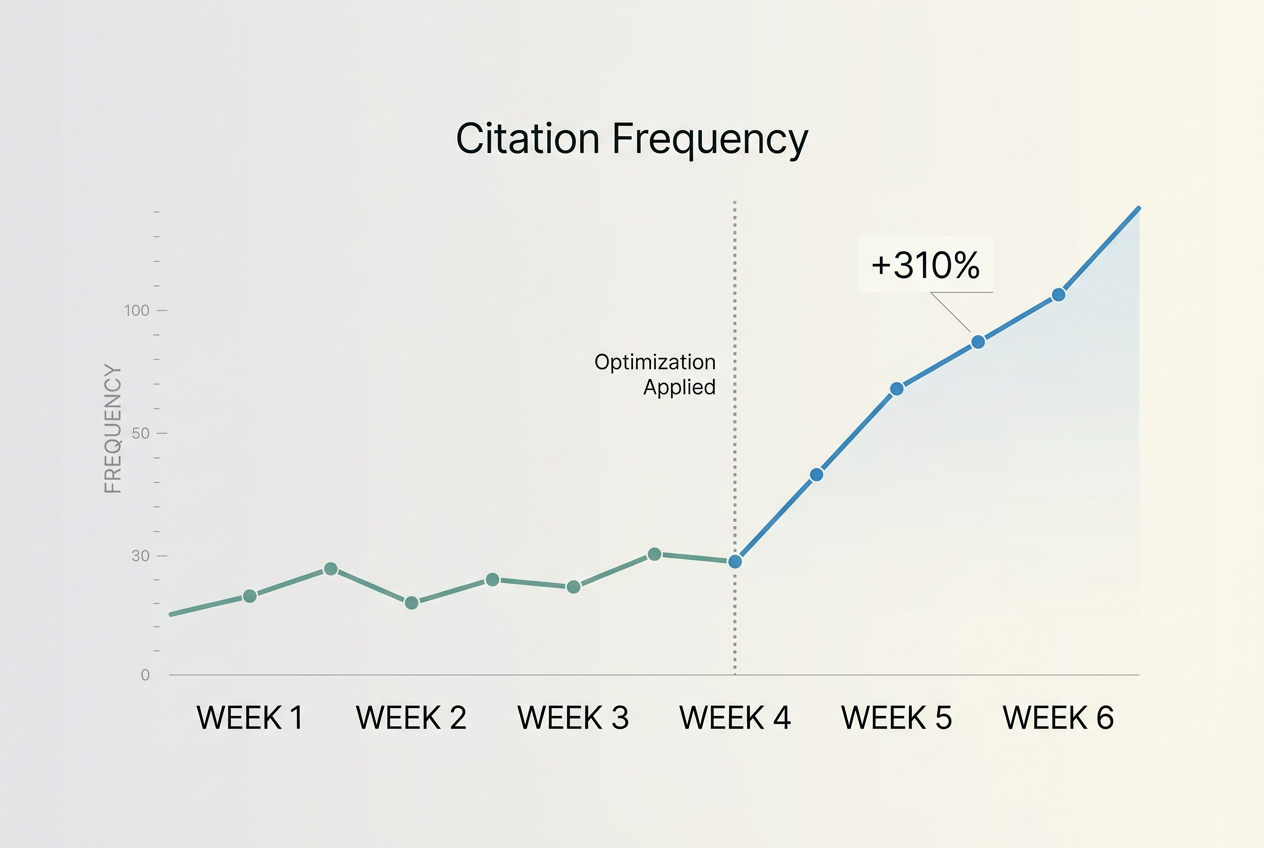
Common Pitfall: Expecting immediate results in the 'base' model. Focus your verification on 'Search' enabled modes. If you aren't showing up there, you won't show up in the next training weights either.
Three Related Tactics to Try Next
Once you have audited your baseline citation visibility, you can move from defense to offense. Here are three tactics to accelerate your GEO performance:
- The 'Statistical Hook' Strategy: Publish a small, original data set every quarter. AI models are hungry for 'new' facts. If you provide a specific statistic (e.g., '45% of SMMs prefer Perplexity over Google'), you become the primary source for that fact across the web.
- The 'Third-Party Validation' Loop: Don't just pitch journalists for the link; pitch them for the 'Entity Association.' Getting mentioned in a 'Best of' list on a high-authority site like Adweek or Search Engine Journal provides a massive citation signal that LLMs use to verify your brand's standing.
- The 'FAQ Injection' Method: Use the 'People Also Ask' data from Google to create an FAQ section on your product pages that uses the exact phrasing people use in natural language search. This aligns your content with the 'Question-Answer' pair format that LLMs are designed to retrieve.
Traditional SEO isn't dead, but it is no longer the ceiling. As AI search continues to fragment the way users find information, your ability to be 'citable' will define your brand's digital relevance. Start with the audit. Find the gaps. Then, build content that isn't just readable, but retrievable.
FAQ